La détresse liée au diabète sur les réseaux sociaux
Mars 2022
La recherche de participants prêts à donner de leur temps pour les études en épidémiologie peut être longue, coûteuse et difficile. L’organisation et les démarches pour les autorisations réglementaires prennent du temps, et il faut contacter et convaincre les volontaires de s’engager durablement.
Pendant ce temps, sur les réseaux sociaux, de nombreuses personnes atteintes de maladies chroniques partagent spontanément publiquement des détails sur leur vécu, leurs symptômes et les difficultés qu’ils rencontrent. Des chercheurs s’intéressent donc à ces messages, dans l’espoir d’y trouver une matière première utile qui peut être complémentaire à l’épidémiologie classique.
Adrian Ahne a consacré sa thèse aux réseaux sociaux, une des nouvelles sources de données qui alimentent un champ émergent de l’épidémiologie qu’on appelle épidémiologie digitale. Après un cursus d’ingénieur, spécialisé en mathématiques et informatique, il vient d’obtenir un doctorat en santé publique, à l’Université Paris-Saclay, sous la direction de Guy Fagherazzi, précédemment directeur scientifique en charge de la 2e génération de l’étude E3N-Générations (anciennement E3N-E4N) et actuellement directeur du département de santé de précision au Luxembourg Institute of Health.
La détresse liée au diabète
Le diabète peut être éprouvant au quotidien. Les personnes atteintes doivent surveiller leur alimentation et surtout leur taux de glucose régulièrement, elles sont parfois contraintes de prendre un traitement régulier et consacrent du temps à leur suivi médical. Tout cela génère souvent une charge émotionnelle, du stress et de l’anxiété et 20 à 25% des personnes avec un diabète souffriraient d’une « détresse liée au diabète ».
Pour « écouter » la conversation de patients et de personnes du public et ainsi mieux comprendre leur vécu de la maladie, Adrian Ahne s’est donc plongé dans 30 millions tweets sur le diabète (qui contenaient des mots clefs faisant référence à la maladie ou à ses traitements), publiés entre 2017 et 2021. A la différence des messages sur d’autres réseaux sociaux, la grande majorité des tweets sont publics, ce qui permet aux chercheurs d’y avoir accès et de les étudier. Pour restreindre un peu le champ d’étude, il a commencé par des tweets en anglais, émis aux Etats-Unis.
Intelligence artificielle et préparation humaine
Bien sûr, 30 millions de tweets, c’est un peu trop de lecture pour un doctorant, d’autant qu’ils contiennent beaucoup de messages non pertinents. Les méthodes de l’intelligence artificielle s’imposent pour ces jeux de données massif. Une étape clé est la présélection de ces tweets, qui permet d’exclure les tweets qui relèvent du spam ou de la publicité pour se concentrer sur ceux qui contiennent des informations plus personnelles. L’étape suivante a consisté à identifier les thèmes de conversation et à décrire les émotions associées dans les 50 000 tweets restant.
L’intelligence artificielle (IA) accélère la prise en main du big data, ce qui n’empêche en rien le travail de préparation d’être parfois long et fastidieux puisque la machine apprend à partir des données préparées par un humain lui servant de modèle. Adrian Ahne a donc « étiqueté » des milliers de tweets afin d’en nourrir ses algorithmes qui devaient identifier des thèmes.
Les tweets étiquetés sont séparés au hasard en deux échantillons : un échantillon pour l’entraînement de la machine et un échantillon « test » pour valider l’efficacité de l’intelligence artificielle entraînée. La très grande diversité des tweets a nécessité de nombreuses répétitions d’étapes d’essais et erreurs pour se concentrer sur les messages les plus pertinents. « Après les premières sessions d’apprentissage, on a découvert de nombreux tweets inattendus : des propriétaires qui s’inquiétaient pour la santé de leur chien, de leur chat, des gens qui blaguaient après un gros repas qu’ils allaient avoir du diabète », s’amuse Adrian Ahne qui a dû entraîner l’IA à filtrer ces messages non pertinents. « C’est un peu le charme de travailler avec le langage, quand on vient de l’univers des mathématiques. »
Les résultats ont montré que, parmi les sujets associés aux émotions négatives dans ces messages sur le diabète, les autres pathologies liés au diabète, la parentalité ou le test oral de tolérance au glucose figuraient en bonne place. Plus frappant, dans l’échantillon américain, un thème ressortait dans un message sur cinq : le prix élevé et l’accès difficile à l’insuline, médicament vital pour le traitement du diabète. L’information a d’autant plus intéresser les chercheurs que les questionnaires standardisés habituellement utilisés pour évaluer la détresse liée au diabète n’interrogeait pas sur ce thème.
« Cela montre la pertinence d’étudier les réseaux sociaux pour soulever des thématiques parfois mises de côté, surtout du point de vue des patients », souligne Adrian Ahne.
De cause à effet
Une étape de plus a consisté à identifier les relations de cause à effet présentes dans les tweets. « Pour pouvoir intervenir et vraiment aider les patients, il est important de comprendre ce qui les effraie, ce qui les stresse, c’est-à-dire comprendre les causes de cette détresse, du point de vue du patient », explique Adrian Ahne.
Reconnaitre des causes et leurs effets dans des phrases est un défi méthodologique, si on cherche à identifier non seulement les causalités explicites (« le diabète me cause des soucis », « le traitement fait peur »), mais aussi des liens implicites (« avec une bonne alimentation, ça va mieux », « C’est bien trop cher, je n’en peux plus »).
Là encore, il a fallu entraîner la machine à les reconnaître en étiquetant manuellement 5000 tweets. « J’ai passé un mois à remplir ligne par ligne un tableau excel de tweets pour y retrouver une éventuelle relation causale, en indiquant les mots qui étaient la cause, ceux qui correspondaient à l’effet, explique le nouveau docteur en santé publique. Je dois dire que c’était une étape très ennuyeuse. » Mais, après le premier entraînement, la machine n’a pas su généraliser la détection des relations causales, à partir de ces 5000 tweets en exemple. « On a alors cherché toutes sortes de solutions pour optimiser l’algorithme et ainsi fournir plus d’exemples de relation cause-effet à la machine, en évitant à tout prix d’étiqueter plus de tweets à la main… Mais ça n’a pas suffi, et il a bien fallu recommencer. »
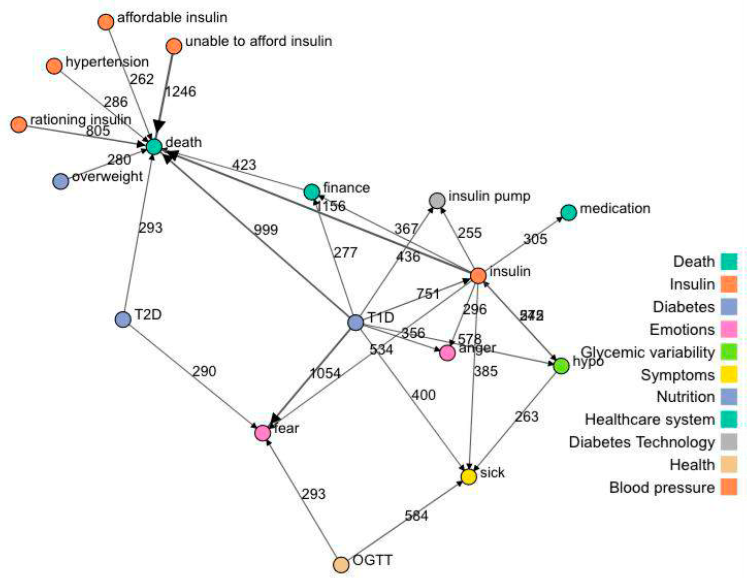
Au centre des conversations sur le diabète dans les tweets étudiés, les 100 000 relations causales identifiés portaient beaucoup sur la mort, le diabète de type 1 et là encore l’insuline, en particulier son prix. Le graphique suivant schématise les principales relations causes-effets retrouvées. « Le nombre des personnes qui s’expriment sur le thème de la mort m’a frappé », souligne Adrian Ahne. De nombreux messages associaient la mort comme effet de nombreuses causes : le diabète de type 1, l’incapacité de se fournir en insuline, l’insuline même, son rationnement et les questions financières.
https://observablehq.com/@adahne/cause-and-effect-associations-in-diabetes-related-tweets
Des réponses plus libres aux questionnaires
« On sait que les réseaux sociaux amènent des biais importants, insiste le chercheur. Pour plusieurs raisons et notamment parce que les personnes qui s’y expriment ne sont pas représentatives de la population, et qu’on connait peu ou pas leurs caractéristiques précises, comme le type de diabète, l’âge ou le sexe. Mais ils permettent au contraire d’intégrer des personnes qui sont peu ou pas inclues dans la recherche classique de type cohorte, notamment des personnes qui vont peu chez le médecin ou certains groupes au profil plus rare. Nos résultats gagneront à être complétés par des recherches par questionnaires, mais on constate déjà que ces sources de données apportent un complément utile aux travaux qui se fondent uniquement sur des questionnaires ».
Les méthodes elles-mêmes offrent un autre intérêt : les questionnaires interrogeant de larges échantillons de personnes comme ceux de l’étude familiale E3N-Générations bannissent généralement les questions ouvertes, où la réponse est libre, faute de pouvoir analyser une quantité massive de texte non formaté et se contentent à la place de choix dans une liste de réponses pré-écrites, plus faciles à analyser. Ces outils d’intelligence artificielle développés pour les messages des réseaux sociaux seraient très utiles pour permettre aux participants de répondre à certaines questions plus spontanément, en texte libre, et donc de pouvoir sortir du cadre posé par les chercheurs… et des biais qu’il amène forcément.

